Neural Transfer Unification (NTU) for quantum error correction
Efficient foundation decoders for fault-tolerant quantum computing
How do we efficiently scale neural decoders? Neural Transfer Unification (NTU) is an architecture-agnostic transfer-learning framework that solves exactly this.
By mapping the scale-invariant structure of QEC codes to learned neural representations,
NTU allows error knowledge from smaller codes to transfer directly to massive fault-tolerant regimes—dramatically reducing compute overhead and completely eliminating the cold-start problem.
1 Nanyang Technological University
2 Tokyo University of Agriculture and Technology 3 Shanghai Jiao Tong University
4 Singapore University of Technology and Design
Fault-tolerant quantum computing relies on protecting logical information (k logical qubits) by redundantly encoding it across a lattice of noisy physical data qubits (n).
The protective capability of the system is governed by the code distance (d), where larger distances exponentially suppress logical error rates.
In practical operations, microscopic physical faults on data qubits cannot be observed directly. Instead, consecutive rounds of stabilizer measurements are executed over time, triggering a sparse sequence of binary detector events.
The locations of these events in the spacetime lattice are called detectors.
The fundamental task of a neural decoder is to process these detector events and accurately infer either the collective logical status or the precise configuration of underlying physical errors.
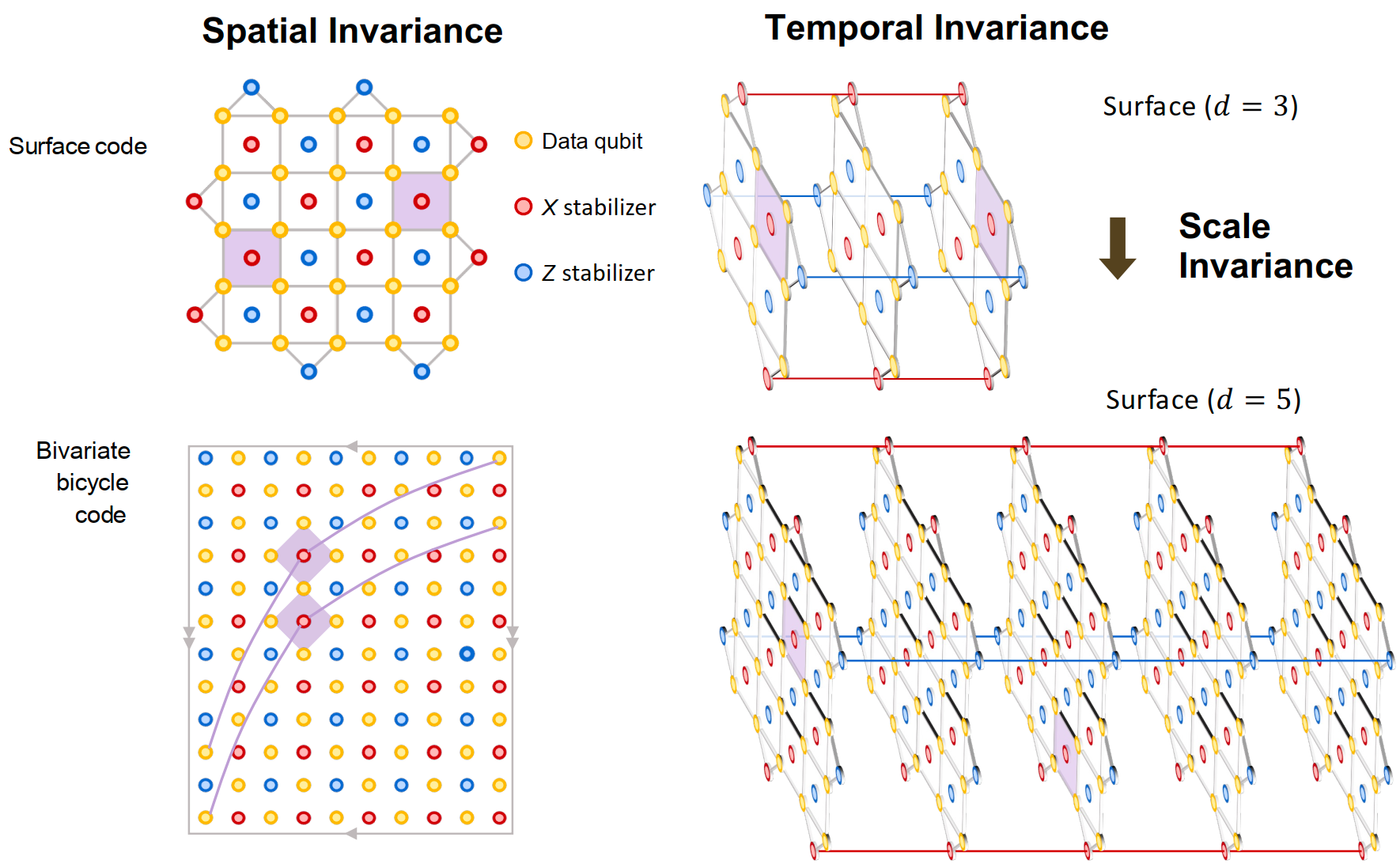
What is scale invariance in QEC code?
In structured quantum code families, such as planar surface codes or quasi-cyclic bivariate bicycle (BB) codes, the parity-check matrix is governed by fixed underlying algebraic generating polynomials.
This mathematical structure yields a strict structural isomorphism across different dimensions.
Within a single measurement round, detectors at different spatial positions share identical local connectivity patterns, exhibiting translation invariance. As measurement cycles repeat, this structure remains uniform over time.
Most importantly, as long as the base generating polynomials remain unchanged, the code possesses native scale invariance.
This means that when the global lattice expands and the code distance $d$ increases, the local topological neighborhood surrounding any specific detector remains rigidly constant.
How does the invariance affect the neural decoder?
Neural decoders process syndrome data by executing representation learning for each detector or data qubit node. This process works by iteratively aggregating and fusing latent features from a node's local neighborhood. This localized computational paradigm is fundamentally isomorphic to the scale, spatial, and temporal invariance of the QEC code.
Because the neighbor connectivity and algebraic shift rules do not change when the code scales, the network parameters optimized for local feature aggregation remain universally applicable across code distances. By explicitly decoupling the network architecture, we ensure that the heavy local perception backbone (which captures the invariant topological motifs) can be seamlessly transferred to massive target lattices without representation collapse.
Scale invariance visualizer
To experience the core mechanism of the NTU framework, start by selecting a base code distance and choose an Error pattern to generate a local cluster of physical errors along with their corresponding detector events. Next, scale up the code distance d via the dropdown menu. You will observe that while the global lattice expands, the localized topological footprint of the detector events remains strictly invariant—demonstrating exactly how local perception motifs seamlessly transfer to larger codes without retraining.
Data Qubit
Physical Error (X/Z)
X-Stabilizer (Idle / Active)
Z-Stabilizer (Idle / Active)
Periodic BB edge
Syndrome display[[49,1,7]] Target
Code Spec[[49,1,7]]
Physical Qubitsn = 49
Logical Qubitsk = 1
Code Distanced = 7
Syndrome Event Count0
Main results
Decoding results for NTU framework on surface and BB codes
To systematically evaluate the performance and cross-distance transferability of the NTU framework, we conduct extensive benchmarks under realistic circuit-level depolarizing noise across two contrasting QEC paradigms: the geometrically local planar surface code and the non-local, high-rate BB code.
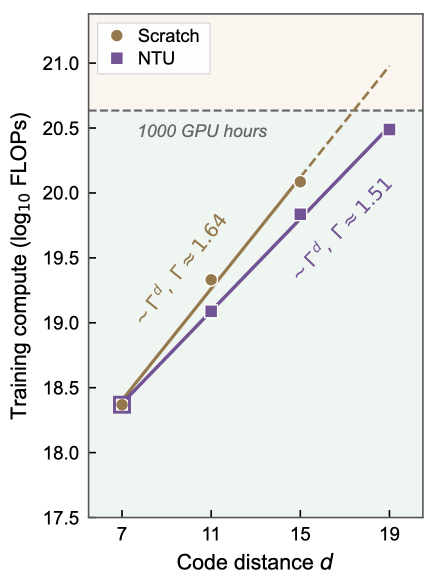
Across both structural code families, the experimental results demonstrate a decisive paradigm shift: while traditional training from scratch suffers from severe optimization roadblocks and prolonged cold-start plateaus as the lattice distance expands, the scale-invariant representations preserved by the NTU backbone yield instantaneous convergence and massive savings in training compute.
Ultimately, these dual-benchmark evaluations establish NTU as a universal, backbone-agnostic route toward scaling up high-capacity foundation decoders for practical, fault-tolerant quantum computation.
Surface code
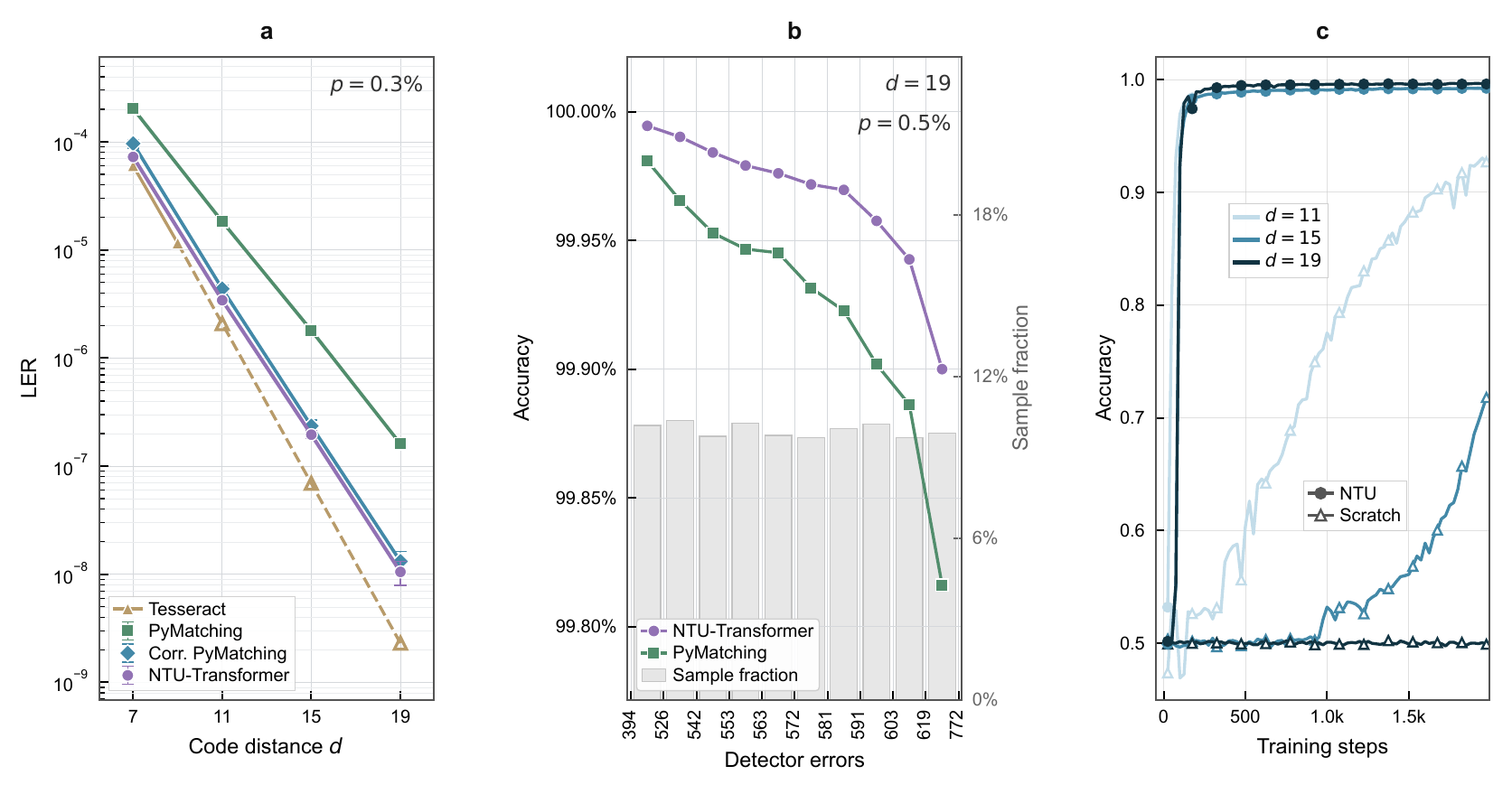
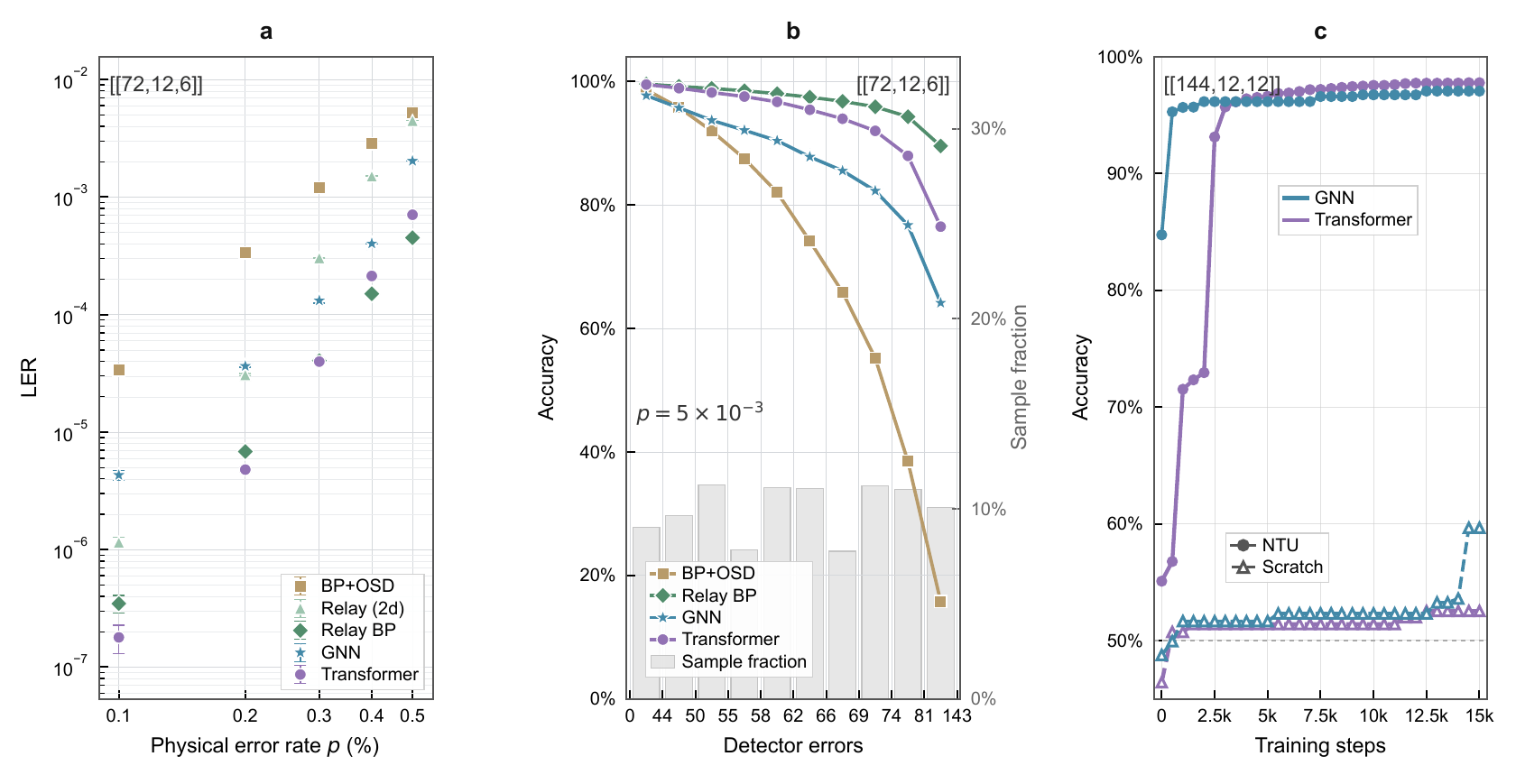
Under a circuit-level depolarizing noise model at p = 0.003, our decoder delivers performance fully comparable to the SOTA correlated PyMatching baseline (Figure a).
When breaking down accuracy by detector-error count, its advantage becomes even more pronounced in high-weight regimes (Figure b).
Most importantly, while training large-distance models from scratch is extremely difficult due to severe cold-start plateaus, the NTU paradigm completely shatters this scaling bottleneck (Figure c)—enabling our high-capacity Transformer model exceeding 30 million parameters to achieve immediate vertical convergence upon initialization.
BB code
On the non-local [[72,12,6]] base code, NTU-Transformer achieves strong performance closely tracking advanced Relay-BP baselines, noticeably outperforming the locally-bounded NTU-NeuralBP (Figure a).
Due to encoding 12 logical qubits simultaneously, training a massive [[144,12,12]] target code from scratch is exceptionally difficult, highlighting the power of the NTU paradigm (Figure c).
The unique step-like accuracy jumps during Transformer fine-tuning reflect the progressive, quantized mastery of independent logical observables.
Interestingly, the NTU-Neural-BP exhibits an instantaneous liftoff because its localized physical error inference rules are completely invariant across graph scales.
Conversely, the global NTU-Transformer requires a brief optimization window to recalibrate its expanded cross-attention readout and adapt its non-local receptive field to the newly expanded boundaries.
Methods
Detailed implementation of NTU
The Neural Transfer Unification (NTU) framework formalizes foundation-decoder construction as an architecture-agnostic transfer learning pipeline.
It bridges varying code distances through four systematized phases: spatiotemporal invariance discovery, distance-independent syndrome encoding, neural representation learning, and targeted domain adaptation.
By shifting the optimization focus from global distance-specific boundaries to localized topological invariants, NTU successfully eliminates curriculum optimization traps and yields scalable decoding precision.
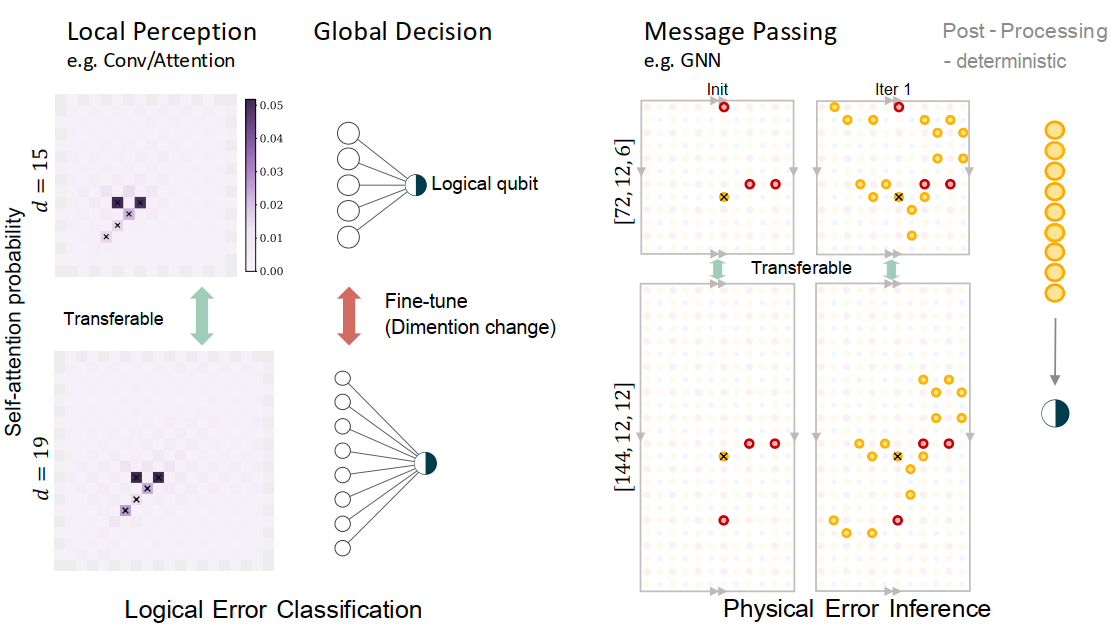
Logical error classification
NTU-Transformer
NTU-Transformer implements a recurrent-Transformer hybrid architecture designed for scalable logical error classification.
To resolve the severe dimensional mismatch where the syndrome input inflates polynomially while the logical output dimension k remains fixed,
the network explicitly decouples into a scale-invariant spatiotemporal perception backbone and a global cross-attention readout.
This structural decomposition enables the heavy feature-extraction weights to be flawlessly transferred across different scales without representation collapse.
Input{0,1}d x mdmd detectors per round
Output[0,1]k
logical error probabilities
01
Relative embedding
Raw sparse binary syndromes are mapped into a continuous latent space via discrete topological lookup tables.
For both geometric surface codes and algebraic qLDPC geometries, the embedding vocabulary is strictly derived from local Tanner graph connectivity complexes and generator intersection matrices.
This guarantees that each embedded token implicitly encapsulates distance-invariant physical neighborhood structures before spatial feature propagation.
02
Rotary positional encoding (RoPE)
To achieve exact structural isomorphism across expanding scales, we implement a geometry-aware RoPE parameterized by unnormalized polynomial-induced matrix coordinates.
By explicitly avoiding boundary-dependent normalization, relative coordinate displacements remain rigidly identical regardless of the target distance d.
The pre-learned high-frequency spectral phase mappings are preserved perfectly across distance updates, isolating fine-tuning to minor boundary boundary adjustments.
03
Gated recurrent unt (GRU)
Temporal fault tolerance across expanding measurement rounds (r = d) is resolved by interleaving Gated Recurrent Units to model noise propagation.
To shatter the optimization plateaus caused by long recurrent paths and label sparsity, we apply continuous step-by-step process supervision.
The backbone is bootstrapped using intermediate pseudo-labels dynamically distilled from a classical heuristic teacher, which is gradually annealed to let the network transcend the classical baseline.
04
Cross-attention readout
The final k-dimensional logical predictions are resolved via a geometry-aware cross-attention pooling mechanism.
Dedicated learnable logical query tokens query the final spatiotemporal stabilizer representations to aggregate distributed global parity evidence.
This structure matches the specific macroscopic operations of the target code family, capturing non-local error correlations linked to the data-qubit support sets.
Physical error inference
NTU-Neural-BP
NTU-Neural-BP instantiates the framework using a parameterized graph neural network (GNN) tailored for localized physical error inference.
Operating directly over the intrinsic bipartite Tanner graph of the QEC code, this paradigm replaces standard classical belief propagation (BP) approximations with learnable, non-linear message passing.
By capturing highly localized correlations, NTU-Neural-BP actively dampens the severe message oscillations and convergence failures traditionally triggered by degenerate short loops within the hypergraph,
directly outputting physical fault probabilities across individual error nodes.
Input{0,1}d × mdmd detectors per round
Output[0,1]Nerr
error-variable probabilities
Message-passing depth
NTU-Neural-BP unrolls a fixed number of neural BP iterations on the detector-error graph.
In our experiments, the depth is set to Niter = 2d, matching the code distance and providing sufficient propagation steps for information to circulate through the sparse decoding graph.
Relation-tied message passing
The model exchanges messages between detector nodes and error-variable nodes.
The same neural message and update functions are shared across graph locations, so the learned rule depends on local graph relations rather than absolute node or edge indices.
When the code size changes, the sparse graph tensors are regenerated while the learned update rules are transferred.
Parameterized aggregation
Neural message updates replace the fixed analytic BP rule with learnable aggregation and state-update functions.
These modules adapt BP-style inference to short cycles, degeneracy, and correlated detector patterns while preserving the sparse graph structure supplied by the detector error model.
Physical readout
The network predicts probabilities over Nerr error variables in the decoding graph.
These error-variable beliefs are mapped through fixed logical maps, which convert the inferred error configuration into predicted logical flips.
Framework extensibility
NTU-Others
The architectural formulation of NTU extends far beyond Transformer and Neural-BP configurations.
The mathematical kernel of NTU dictates that any high-capacity neural decoder can seamlessly leverage cross-distance knowledge transfer, provided its underlying backbone executing the syndrome processing relies on localized representation learning.
For example, convolutional neural networks (CNNs) capturing translation invariants or graph convolutional networks (GCNs) operating on detector graphs both utilize purely localized information aggregation.
Because their computational footprints are structurally decoupled from global code scale expansions, these alternative deep learning paradigms are fully compatible with the NTU framework—serving as a universal scaling foundation for quantum error correction.
Reference
Citation
@misc{yan2026efficientfoundationdecoders,
title = {Efficient foundation decoders for fault-tolerant quantum computing},
author = {Yan, Ge and Li, Shanchuan and Xiao, Shiyi and Ma, Pengyue and Cao, Hanyan and Pan, Feng and Du, Yuxuan},
year = {2026}
}
Paper and code assistant
Ask about NTU Decoder
Backend not connected yet. Deploy the Cloudflare Worker, then replace the endpoint in index.html.
Ask about the paper, the NTU-Transformer implementation, baselines, training script, or BB-code circuit generator.